Query Understanding for Search
- Query Understanding for Search
Made up of multiple blocks
To transform a raw, noisy user string into useful string that can be better used to serve our user.
Standard Flow:
Raw Query $\rightarrow$ Correction $\rightarrow$ NER/Tagging $\rightarrow$ Intent Class $\rightarrow$ Weighting $\rightarrow$ Expansion $\rightarrow$ Retrieval
- Pre-processing: Cleaning query, spell correction.
- Structural Analysis: Named Entity Recognition (NER).
- Semantic Analysis: Intent Classification, Term Weighting.
- Enrichment: Query Expansion, Rewriting.
Query Rewriting & Correction
This module handles input errors to ensure downstream tasks receive valid tokens.
Error Classification
- Homophones: Same pronunciation, different meaning (e.g., piece vs peace).
- Ambiguous Sounds: Phonetically similar but not identical.
- Visual Similarity: Character stroke similarity (common in OCR or CJK {CJK refers to Chinese Japanese Korean} languages).
- Non-word Errors:
- Permutations:
fiappy$\rightarrow$flappy - Numeric:
2408$\rightarrow$2048
- Permutations:
- Word Errors:
- Omission:
apple 17$\rightarrow$apple iphone 17 - Reversal:
Throne of Games$\rightarrow$Game of Thrones
- Omission:
Algorithmic Approach: HMM & Viterbi
Term Weighting: Math Derivations (Click to expand)
For error correction, we model the problem using a Hidden Markov Model (HMM).
We treat the intended correct words as the hidden states and the user’s typed query as the observations.
We aim to find the sequence of intended words $W = (w_1, w_2, …, w_n)$ that maximizes the probability of the observed query $O = (o_1, o_2, …, o_n)$.
\[\hat{W} = \underset{W}{\text{argmax}} P(W | O)\]Using Bayes’ Theorem:
\[\hat{W} = \underset{W}{\text{argmax}} \frac{P(O | W) P(W)}{P(O)}\]Since $P(O)$ is constant for ranking candidates, we maximize:
\[\hat{W} \approx \underset{W}{\text{argmax}} \prod_{i=1}^{n} \underbrace{P(o_i | w_i)}_{\text{Emission}} \cdot \underbrace{P(w_i | w_{i-1})}_{\text{Transition}}\]Emission Probability:
$P(o_i \mid w_i)$
The probability that a user types $o_i$ when they intended $w_i$.
This models the “Noise Channel” (e.g., keyboard layout distance, phonetic edit distance).
Transition Probability:
$P(w_i \mid w_{i-1})$
The probability of word $w_i$ following $w_{i-1}$.
Named Entity Recognition (NER)
NER transforms unstructured text into structured slots. This is critical for queries with multiple constraints (e.g., travel or e-commerce).
Example: “mumbai bangalore evening flight”
Without NER, this is a bag of words. With NER, the query is parsed into a structured object:
| Token | Entity Tag | Semantic Role |
|---|---|---|
| mumbai | LOC_CITY |
origin |
| bangalore | LOC_CITY |
destination |
| evening | TIME_RANGE |
departure_time |
| flight | CATEGORY |
product_type |
Approaches:
Not really sure, will need to read more of it.
- Linear CRF (Conditional Random Fields): Classic approach for sequence labeling.
- Bi-LSTM-CRF / BERT: To capture bidirectional context.
Structured Search
Adds structure to your search, takes raw user queries and identifies key components. Well yes this is similar to NER, in this section we’ll only cover about this feature in the context of marketplace search.
Note: this is not about carousell, this section is inspired by the Meituan Search doc which is mentioned in the acknowledgements section as well.
There are offline and online components to this functionality. We compute and store values observed historically (either through prev searches or through information provided by sellers on our platform, for Meituan this could be anything from restuarants, hotels to grocery stores). A big issue highlighted in the article talks about incorrect retreival, which can pollute our results and surface irrelevant listings, ruining user experience. A query for ‘KFC’ might also return a barbershop, with it’s landmark being ‘near KFC’ which is a genuine problem.
For folks in Bangalore, you might be aware of ‘Indiranagar KFC’ which serves as the landmark for quite a lot of stores. (across/opposite to KFC, beside KFC, near KFC).
Overall architechture
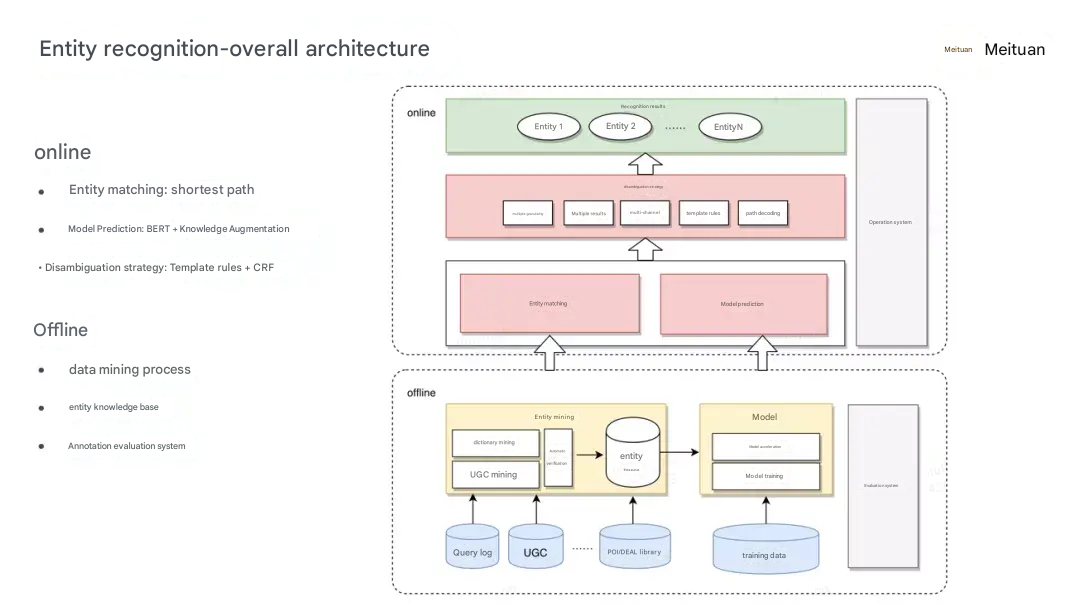
Intent Recognition
To determine the user’s goal. Deals with ambiguity where one term maps to multiple domains
(e.g., “Apple” $\rightarrow$ Fruit vs. Electronics).
Types of Intent
-
Precise Intent:
High confidence, usually specific entity searches (e.g., “iPhone 15 Pro Max”).
Long-tail queries fall here and often suffer from sparse behavioral data. -
Ambiguous Intent:
Broad queries (e.g., “best gifts”).- Strategy: Treat as a Multi-Label Classification task.
- Features: Correlate query terms with clicked product categories from historical logs.
Term Importance (Weighting)
Not all words in a query carry equal weight. Can classify terms into:
- Core Terms: Essential for retrieval (removal changes intent).
- Qualifiers: Refine the search (e.g., colors, sizes).
- Noise: Stop words or conversational filler.
Statistical Metrics for term importance
1. Neighbor Entropy Measures the diversity of terms that appear to the left/right of a target term.
- High Entropy: The term appears in many contexts
e.g., “iPhone” can be followed by case, charger, screen. $\rightarrow$ Core/Ambiguous. - Low Entropy: The term has very few valid neighbors
e.g., “Defragmenting” is almost always followed by “disk”. $\rightarrow$ Specific/Niche.
2. Independent Search Ratio Quantifies how often a term is searched alone versus as part of a phrase.
\[\text{ISR}(t) = \frac{\text{count}(t)}{\text{count}(t \in \text{supersets})}\]- Example:
troubleshooting. If users rarely search this word alone, but always searchrouter troubleshooting, the ISR is low, indicating it is a dependency term.
Embedding-Based
To determine term $t$’s importance in query $Q$, we can compare the semantic vector of the full query against the query without the term.
Method A: Naive Subtraction \(\text{Score} = || \vec{V}_{Q} - (\vec{V}_{Q} - \vec{V}_{t}) ||\)
- Logic: Subtract term vector from pooled query vector. Large resultant change implies high importance.
- Latency: Ultra-low. Simple element-wise operation.
- Drawback: Vector subtraction in high-dimensional space often yields geometrically meaningless results in semantic models (like BERT).
Method B: Cosine Similarity \(\text{Importance} = 1 - \text{CosineSimilarity}(\vec{V}_{Q}, \vec{V}_{Q \setminus \{t\}})\)
- Logic: Embed the full query. Embed the query excluding term $t$. Calculate similarity.
- High Similarity $\rightarrow$ Term $t$ didn’t add semantic value (Noise).
- Low Similarity $\rightarrow$ Term $t$ changed the meaning significantly (Core).
- Latency: Higher than subtraction (requires Dot Product and Norm calculations).
However, for short queries ($<10$ tokens), the overhead might be negligible.
Query Normalization & Synonyms
Goal: Align user vocabulary with catalog SKUs (e.g., sneakers $\rightarrow$ shoes).
Challenge: Distinguishing “Synonyms” (semantic equivalents) from “Related Concepts”.
- Synonym: Cell phone $\leftrightarrow$ Mobile Phone.
- Related: iPhone $\leftrightarrow$ Apple.
Solution: Cosine Thresholding & Graph Constraints Mining synonyms via simple co-occurrence or embedding similarity often captures “Related” terms erroneously.
- Strict Thresholds: Set
Cosine Similarity > 0.Kfor synonyms,0.slighty_less_than_K - 0.Kfor related terms. - Knowledge Graph: Enforce constraints. If
Term AandTerm Bshare the same parent node in a taxonomy (e.g., both are children ofBrand), they are likely siblings/substitutes, not synonyms.
Query Suggestions
As the request volume is massive, suggestions are usually pre-computed, using a prefix tree / trie. For retrieval we can store this in a Top-K Min Heap.
Ranking Criteria:
- Historical Volume: What did others search? (Bias: Hard for new trends to surface).
- CTR (Click-Through Rate): If a suggestion leads to a result page with valid clicks, boost its score.
Acknowledgements
- Based on concepts from Zhihu Blog - Query Understanding
- Nothing else honestly, blogs on Zhihu are quite comprehensive, if you can somehow choose to ignore their 10 thousand sign up requests.
- Structured Search at Meituan, which is an O2O (online to offline) marketplace.